SIMULIA 2026新功能直通车|Abaqus HPC新功能介绍
日期:2026-01-27 发布者: 达索系统 浏览次数:次

01、Abaqus/Standard求解器HPC性能更新介绍
在Abaqus 2026x隐式求解器高性能计算的新功能更新说明中,主要介绍了AMG迭代求解器在不同软件版本中的性能提升,并且同隐式直接求解器进行了计算性能的比较。
为了测试不同规模的模型在HPC中的性能提升表现,选取了4个SIMULIA的中型、大型标准测试模型,在Abaqus隐式求解中分别使用直接求解器和AMG迭代求解器进行求解效率的性能比较。
| 动力总成模型 | ||
单元数:560万 自由度数:3700万 | 自由度数:5100万 | |
自由度数:1.32亿 | 单元数:2750万 自由度数:1.25亿 |
通过Abaqus新旧软件版本(2024x VS 2026x)、不同求解器(Direct求解器 VS AMG迭代求解器)、不同分布式节点并行环境、不同通信架构(OMPI VS IMPI)等方面开展评估:
2024x版本中,传统的直接求解器需要消耗约TB量级的内存,对于大型模型计算会因为内存溢出而失败;而AMG迭代求解器对内存的需求大大降低,可从TB量级降低到GB量级;同直接求解器相比,仅需相对少量内存即可稳定运行完成计算,将硬件门槛降低了约60%以上,此外相较于直接求解器上千秒甚至无法计算的情况,AMG迭代求解器的计算时间仅需要约百秒左右,计算效率提升约80%。
与2024x版本相比,2026x版本的Abaqus中的AMG迭代求解器的性能进一步提升。仿真计算时间根据计算分布节点数量的不同,计算效率可实现3-6倍的提升,计算内存的消耗也比24x版本节省约40%左右,极大缩短了企业研发迭代周期和降低了研发成本;
2026x新版本的AMG迭代求解器在OpenMPI与IntelMPI通信环境下均表现出一致的求解稳定性。相同计算模型在不同节点(如4、6、8、12节点等)的高性能计算性能评估中,内存使用及管理与计算时间表现无太大差异。
Abaqus 2026x新增Homogeneous Batch并发模式,主要考虑了同一模型在进行少量参数修改后进行的多次大规模计算场景下的计算性能表现的提升。
测试中选取了s4e标准测试模型,即模型自由度为1500万的动力总成模型,并对模型进行不同的参数修改,最终将若干个此模型的计算文件打包提交,测试在有限计算资源(如100个计算节点)下如何在一天内完成尽量多的计算任务。测试结果表明,对于单个计算任务,CPU数量越多,计算完成的时间越快,但是每天完成的总计算任务并不是最多的。通过测试,当单任务计算选取32或64核心进行计算提交时,计算节点的资源可以100%充分使用,集群无排队且每天完成的计算任务数最多。
与此同时,License的投入会减少,所有的计算任务共享1个许可,以单任务64核计算核心为例,单位许可产出1.55计算任务/天,比传统“一任务一个许可”的配置模式的单位许可产出效率高。
02、Abaqus/Explicit求解器GPU加速性能更新介绍
在Abaqus 2026x新功能介绍中,首次在业界推出面向通用显式有限元分析求解器的GPU加速介绍,此部分功能更新还在持续研发过程中。在本次发布中,首先重点确保了显式求解器GPU加速后的计算结果与纯CPU求解的精度一致性;在以单元计算为主的仿真场景(如冲击、碰撞、跌落等瞬态动力学分析)中,加速效果明显;支持跨多个节点的多GPU分布式计算,但现阶段软件版本仅支持Linux系统上的NVIDIA GPU的显式求解加速。
通过对e10、e11、e13、e14标准测试模型的测试结果显示,相同CPU计算数量、增加1个GPU进行计算,求解效率可以提升约54%,若增加一个计算节点,比如由1个计算节点下的2个GPU,增加到2个计算节点的4个GPU,求解效率可以提升约54%-62%。
在本次Abaqus 2026x的发布版本中,基于研发的阶段开发和测试结果,给出了一些显式求解器的GPU加速建议:
对于大模型计算,建议使用多节点和多GPU。对超大规模模型计算,可考虑扩展至1000CPU以上。现阶段测试显示可以对三亿以上自由度的大模型计算进行加速处理;
单个CPU处理的网格数超过6000时,建议使用HMP模式;
Inter单节点处理器条件下,建议使用SMP;
为仿真设置适当的求解精度:
长物理时间求解且包含大量增量步时:double=explicit
以约束为主导的问题:double=constraint
一般工况:double=off
极端情况工况double=both
值得注意的是,此功能更新效果取决于具体的求解流程和场景,不同分析模型获得的加速效果会不尽相同。随着后续持续研发,此部分功能会有进一步的功能更新内容发布。
03、Abaqus分布式并行架构(DMP)协同仿真服务(CSS)性能更新介绍
Abaqus 2026x新版本功能介绍中,更新了DMP架构下的CSS多物理场协同仿真服务性能提升介绍,尤其是大规模耦合计算的性能提升和稳定性表现。
新版本中,从协同仿真服务(CSS)的架构层面进行了改进,推出了基于DMP分布式的CSS架构。新的基于DMP的CSS架构通过分布式内存并行技术,将CSS从传统的单进程协调模式转变为分布式并行模式,实现了大规模多物理场耦合仿真的性能提升。
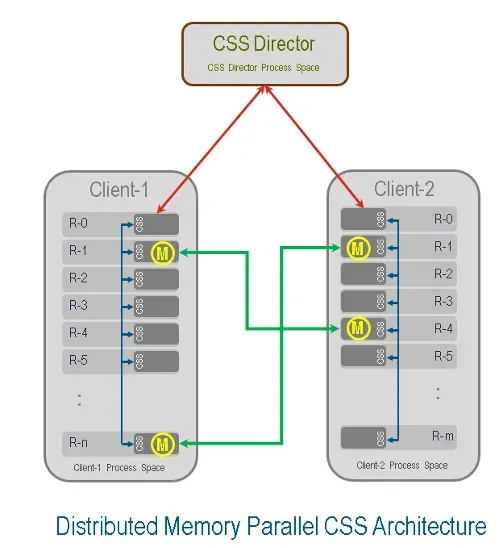
新的DMP CSS架构下,性能提升具体表现在:
场数据在多个计算进程间并行传输和数据交换,消除了根进程数据传输的瓶颈;
场数据映射可分布式并行执行,大幅提升了数据的映射效率;
自动数据管理,开发者无需手动处理数据扇入/扇出,降低开发复杂度;
针对大模型的大规模体积数据映射和耦合效率进行了优化,支持更复杂物理问题的求解,实现了大规模多物理场耦合仿真的性能飞跃和效率提升。
功能更新说明中最后给出若干案例,案例模型涉及到上下游体数据的映射、大规模网格且网格节点不协调等。传统的串行协调模式下,要实现如此大规模的体数据映射非常困难,或者只能实现粗略网格的体数据映射,而在新版本的DMP并行CSS架构下,可以完成精细网格下的大规模体数据的映射。

将FMK热传计算得到的温度场映射到Abaqus的体网格,流体网格和体网格的节点不匹配
Abaqus 2026 精彩不断
其他详细功能更新敬请关注代理商智诚科技ICT官网,也可以联系我们技术热线:400-886-6353 了解最新信息!
获取正版软件免费试用资格,有任何疑问拨咨询热线:400-886-6353或 联系在线客服
未解决你的问题?请到「问答社区」反馈你遇到的问题,专业工程师为您解答!